程序是怎么执行的?
# 文件在磁盘上的保存
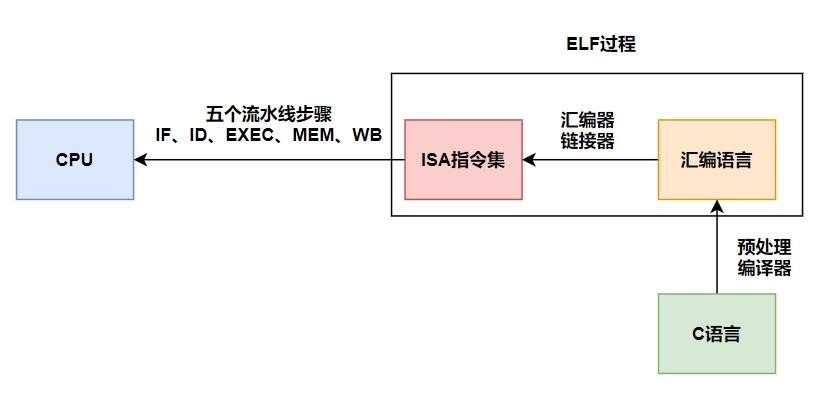
这里的汇编器可以产生出几种文件:
.o文件:静态链接库- 两个或多个文件合成一个含有main的可执行文件,为何需要main呢?因为当CPU加载程序需要执行时,需要
IP寄存器指向执行的代码,而main就是程序内部逻辑开始执行的初始地方(注意:不是指程序执行的第一行,而是程序内部逻辑的初始位置)。 - 是地址相关的,因为将这些小的区域的代码合并为一个大的文件时,会出现地址转变,于是通过一个映射表(rela_sym)来记录需要转换的地址,从而在链接阶段对地址进行更改 —— 地址重定位。
- 静态链接是所有程序需要的内容都在一个文件中,可以使用绝对地址来表示
- 两个或多个文件合成一个含有main的可执行文件,为何需要main呢?因为当CPU加载程序需要执行时,需要
.so文件:动态链接库- 是地址无关的,使用 绝对地址 和 GOT中转表做地址映射,因为每个程序中的动态链接库的地址是不同的,所以需要针对每个进程有一个 GOT中转表,记录在该进程内链接库的地址。
.out文件:可执行文件
# 程序的排布
上述讲的内容完成了磁盘上存储文件的闭环了,但是在内存中的排布还不知道。
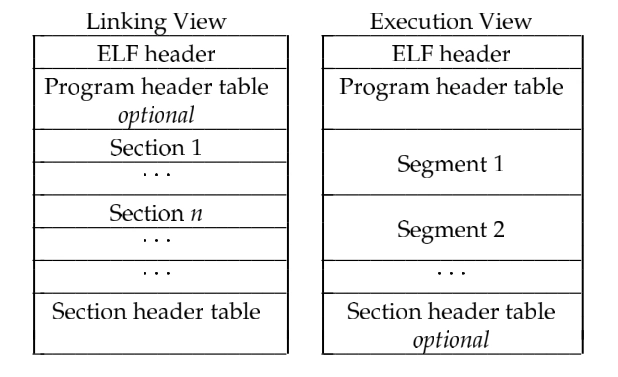
ELF header:指明一些基础数据,如版本、类型、入口地址,大小......
An ELF header resides at the beginning and holds a "road map'' describing the file's organization. Sections hold the bulk of object file information for the linking view: instructions, data, symbol table, relocation information, and so on.
译:一个ELF 头部放在文件的开始位置,并且持有一个 “路线图(标识了元数据信息在哪里,元数据:表示了数据的数据)” 描述文件的组织,这些节部分持有目标文件的大部分信息:指令、数据、符号表、重定位信息等等,
节头部表:用于表示有哪些节,在哪里
A section header table contains information describing the file's sections. Every section has an entry in the table; each entry gives information such as the section name, the section size, and so on. Files used during linking must have a section header table; other object files may or may not have one.
译:一个节头部表包含了描述文件中的节的信息,每一个节有一个项目都在该表中存在一个表项,每个表项给定该节的信息如:节的名字,节的大小 以及其他内容。文件使用在链接过程中必须有一个节头部表,其他阶段则不是必须的。
段头部表:用于表示有哪些段,在哪里
程序头部表:
A program header table, if present, tells the system how to create a process image. Files used to build a process image (execute a program) must have a program header table; relocatable files do not need one.
译:一个程序头部表告诉操作系统如何去创建一个内存映像(加载到内存成为一个程序),文件被用于去构建程序映像(即执行一个程序)必须有一个程序头部表,可重定位的文件(.o文件)不需要。
链接视图上呢,就是一个个的 .o、.so文件,其中使用.section做一个个节,当链接为一个可执行文件后,.section就没有了,替换掉的是.segment段。
我们看到在链接文件中,程序头部表是不重要的,但是在执行视图中,程序头部表却是必须的,那么他一定有很重要的用途,那么什么是程序头部表呢???
# 程序头部表
通过 readelf打印下可执行文件的头部信息
[root@origin demo]# readelf -l a.out
Elf 文件类型为 EXEC (可执行文件)
入口点 0x400550
共有 9 个程序头,开始于偏移量64
程序头:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x000000000000082c 0x000000000000082c R E 200000
LOAD 0x0000000000000e00 0x0000000000600e00 0x0000000000600e00
0x0000000000000234 0x0000000000000240 RW 200000
DYNAMIC 0x0000000000000e18 0x0000000000600e18 0x0000000000600e18
0x00000000000001e0 0x00000000000001e0 RW 8
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x0000000000000700 0x0000000000400700 0x0000000000400700
0x0000000000000034 0x0000000000000034 R 4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x0000000000000e00 0x0000000000600e00 0x0000000000600e00
0x0000000000000200 0x0000000000000200 R 1
Section to Segment mapping:
段节...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .dynamic .got
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# Load
注意:这里有两个 LOAD
关于Load项我们通过 ELF 文档可以查询到
The array element specifies a loadable segment, described by p_filesz and p_memsz. The bytes from the file are mapped to the beginning of the memory segment. If the segment's memory size (p_memsz) is larger than the file size (p_filesz), the "extra'' bytes are defined to hold the value 0 and to follow the segment's initialized area. The file size may not be larger than the memory size. Loadable segment entries in the program header table appear in ascending order, sorted on the p_vaddr member.
译:这个数组元素指定一个可加载到内存的段,描述了文件大小和所需内存位置,这些来自文件中的bytes被映射奥内存段的其实位置,如果段的内存大小要大于文件大小,那么多余的部分将会使用0来填充。文件的大小不会大于内存大小。……
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x000000000000082c 0x000000000000082c R E 200000
2
注意这个load项,是 可读 和 可执行的,而我们知道的段(代码段、数据段、堆栈段)也就只有代码段是可读可执行的了,所以这里是指将代码段放置到 0x400000 (4mb)的位置,并且是按内存地址是升序的。即:
# 64bit
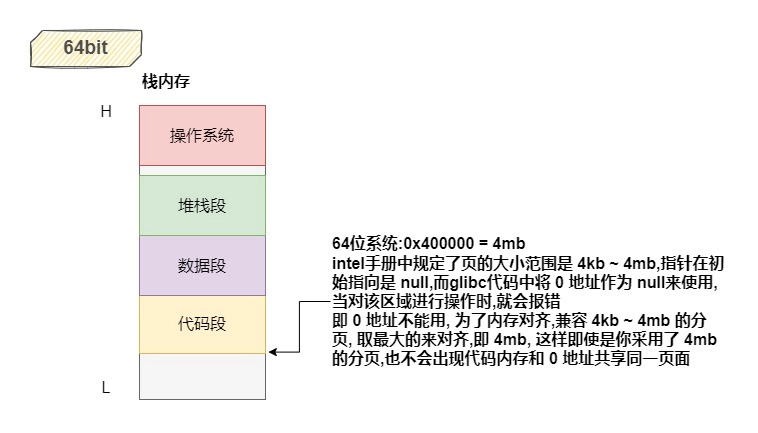
有人可能会说,我4mb直接不用了会不会存在内存浪费呢?其实在 64位机上,地址是足够用了的,并且这里的地址只是虚拟地址,所以不存在什么地址空间浪费的问题。
# 内存对齐
讲到内存对齐问题就得查看为什么要进行内存对齐:
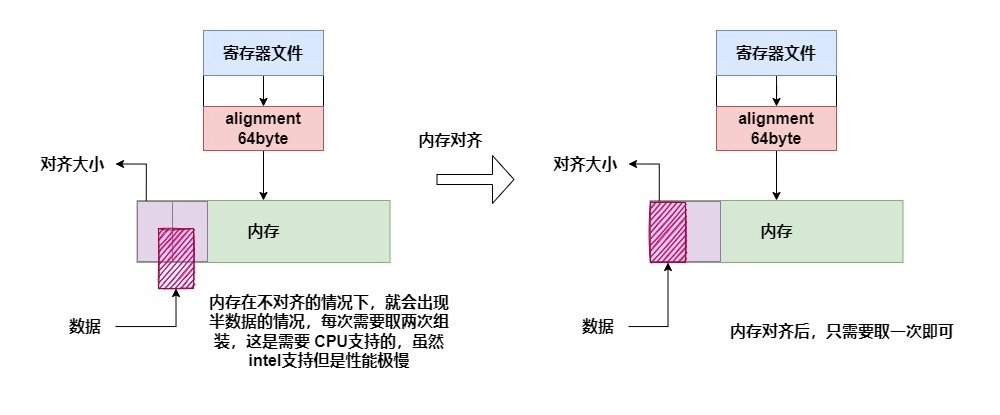
通过《intel手册验证》:
# Alignment of Words, Doublewords, Quadwords, and Double Quadwords
Words, doublewords, and quadwords do not need to be aligned in memory on natural boundaries. The natural boundaries for words, double words, and quadwords are even-numbered addresses, addresses evenly divisible by four, and addresses evenly divisible by eight, respectively. However, to improve the performance of programs, data structures (especially stacks) should be aligned on natural boundaries whenever possible. The reason for this is that the processor requires two memory accesses to make an unaligned memory access; aligned accesses require only one memory access. A word or doubleword operand that crosses a 4-byte boundary or a quadword operand that crosses an 8-byte boundary is considered unaligned and requires two separate memory bus cycles for access.
译:字、双字 和 四字 不需要去对齐到内存的自然边界上,这些的自然边界是偶数地址,地址可以分别被4整除 和 被8整除。然而为了提高程序性能,数据结构(尤其是栈)应该尽可能对齐到自然界限。原因是对于没有对齐的数据处理器需要两次访问内存,而对齐的数据只需要一次内存访问,一个字或双字操作穿过4字节自然界限 或者是 双字 操作越过 8字节的自然内存 由于 内存的不对齐 将会 请求两次分离的内存总线 周期
Some instructions that operate on double quadwords require memory operands to be aligned on a natural boundary. These instructions generate a general-protection exception (#GP) if an unaligned operand is specified. A natural boundary for a double quadword is any address evenly divisible by 16. Other instructions that operate on double quadwords permit unaligned access (without generating a general-protection exception). However, additional memory bus cycles are required to access unaligned data from memory.
译:一些操作双字的指令需要内存操作在自然界限上对齐。这些指令产生一个 GPE 当进行非内存对齐的操作。一个双字在内存中的位置应该能被 16 整除。其余操作双字的指令允许非对齐的内存访问(不会产生GPE)。然而操作内存中非对齐的数据需要额外的内存总线周期。
# 32bit
前面说了 64位机器是对齐到 0x400000 地址处,是为了进行内存对齐,那么32位机器呢?
32位机器上是在 0x804800对齐的,那这又是为什么呢? —— 历史原因
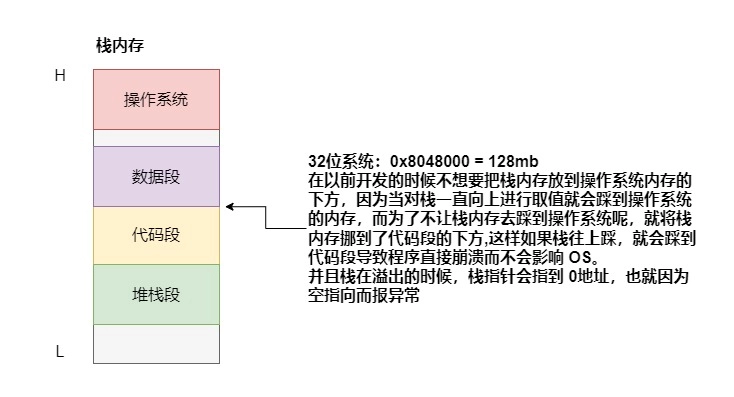
在以前开发的时候不想要把栈内存放到操作系统内存的下方,因为当对栈一直向上进行取值就会踩到操作系统的内存,而为了不让栈内存去踩到操作系统呢,就将栈内存挪到了代码段的下方:

# INTERP
The array element specifies the location and size of a null-terminated path name to invoke as an interpreter.
译:这个数组元素表明了 一个有效的路径名字去调用一个链接器 的 位置 和 大小
# 程序执行的第一行代码
我们通过 readelf -l查看程序的头部表,因为程序的头部表描述了文件的组织等一些列信息:
[root@origin demo]# readelf -h a.out
ELF 头:
// 。。。。。
入口点地址: 0x400550
// ……
2
3
4
5
注意这里标明了程序的入口地址 -> 0x400550,然后我们通过将文件反汇编就可以看到该地址对应的代码内容
[root@origin demo]# objdump -d a.out
a.out: 文件格式 elf64-x86-64
// ……
0000000000400550 <_start>:
400550: 31 ed xor %ebp,%ebp
400552: 49 89 d1 mov %rdx,%r9
400555: 5e pop %rsi
400556: 48 89 e2 mov %rsp,%rdx
400559: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
40055d: 50 push %rax
40055e: 54 push %rsp
40055f: 49 c7 c0 e0 06 40 00 mov $0x4006e0,%r8
400566: 48 c7 c1 70 06 40 00 mov $0x400670,%rcx
40056d: 48 c7 c7 3d 06 40 00 mov $0x40063d,%rdi
400574: e8 a7 ff ff ff callq 400520 <__libc_start_main@plt>
400579: f4 hlt
40057a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
// ……
000000000040063d <main>:
40063d: 55 push %rbp
40063e: 48 89 e5 mov %rsp,%rbp
400641: b9 04 00 00 00 mov $0x4,%ecx
400646: ba 03 00 00 00 mov $0x3,%edx
40064b: be 02 00 00 00 mov $0x2,%esi
400650: bf 01 00 00 00 mov $0x1,%edi
400655: b8 00 00 00 00 mov $0x0,%eax
40065a: e8 e1 fe ff ff callq 400540 <func@plt>
40065f: c7 05 cb 09 20 00 64 movl $0x64,0x2009cb(%rip) # 601034 <global_data>
400666: 00 00 00
400669: b8 00 00 00 00 mov $0x0,%eax
40066e: 5d pop %rbp
40066f: c3 retq
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
通过该反汇编代码,我们发现main函数的地址是:000000000040063d,而并非入口地址,则main函数肯定不是程序执行的第一行代码,我们继续观察,发现程序执行的第一行代码的地址是:_start ,然后该函数中又调用了<__libc_start_main@plt>函数,即:main函数肯定是通过汇编器生成的代码去调用的。而要验证这一点就需要去查看 _start的代码。
于是我们就需要去查看 GLIBC 的代码了。
/* This is the canonical entry point, usually the first thing in the text
segment. The SVR4/i386 ABI (pages 3-31, 3-32) says that when the entry
point runs, most registers' values are unspecified, except for:
%edx Contains a function pointer to be registered with `atexit'.
This is how the dynamic linker arranges to have DT_FINI
functions called for shared libraries that have been loaded
before this code runs.
%esp The stack contains the arguments and environment:
0(%esp) argc
4(%esp) argv[0]
...
(4*argc)(%esp) NULL
(4*(argc+1))(%esp) envp[0]
...
NULL
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
注释译:这是一个规范的入口点,通常是代码段中的第一个部分,在 《SVR4/i386 ABI》 (pages 3-31, 3-32) 中提到当程序开始执行到该入口点,大多数寄存器的值都未指定,除了以下寄存器:
edx:包含一个函数指针 —— “atexit”,这是动态链接器安排的去持有
DT_FINI方法 去处理哪些在代码执行前被加载到内存的共享库esp:栈中包含一些参数和环境
- argc
- argv[]
- null
- envp[]
什么是 ABI 呢?
# application binary interface (ABI)
The set of runtime conventions followed by all of the tools that deal with binary representations of a program, including compilers, assemblers, linkers, and language runtime support. Some ABIs are formal with a written specification, possibly designed by multiple interested parties. Others are simply the way things are actually done by a particular set of tools.
译:是处理程序二进制表示的所有工具遵循的一组运行时约定,包括编译器、汇编器、链接器 以及语言运行时支持。一些 ABI 是正式的编写规则,可能有多个相关方设计。
其实就是一组规范,让 一整个工具即都根据该规范进行实现。